基于制药废水处理过程中安全与能耗并存的突出矛盾,结合马尔可夫决策过程环境建模,采用深度确定性策略梯度算法对工艺参数进行动态优化。以某制药企业小型 A/O 处理系统为案例,针对进水波动,通过强化学习实现集水池 pH、溶解氧等多参数的联动控制。试验数据显示,系统在出水达标率、能耗和冲击负荷响应等方面均实现了显著优化,污泥膨胀及设备异常事件明显减少。
制药工业是我国重要的民生产业,如果制药废水处理不当,那么将会严重威胁生态环境和人体健康 [1]。目前,制药废水处理普遍存在操作复杂、能耗高和易发生事故等问题。为了解决上述难题,本文提出基于强化学习的制药废水处理工艺安全优化控制系统,旨在实现制药废水处理工艺的安全高效运行。
某制药企业现有制药废水处理系统设计处理规模为30m3/d,采用“预处理 + 生化处理”的组合工艺路线。其中预处理单元包括格栅井、集水池,集水池容积 10m3,生化处理单元采用两级 A/O 工艺,一级 A/O 池容积 15m3,设计水力停留时间(Hydraulic Retention Time,HRT)为 18h,二级 A/O 池容积 12m3,设计 HRT 为 14h。进水水质监测数据显示,化学需氧量(Chemical Oxygen Demand,COD)浓度为 2500mg/L~4000mg/L,氨氮浓度为 80mg/L~150mg/L,总氮浓度为 150mg/L~250mg/L。出水水质监测数据显示,COD 浓度为 300mg/L~500mg/L,氨氮浓度为 30mg/L~50mg/L,总氮浓度为 50mg/L~80mg/L。系统已连续运行 1 年以上。
制药废水具有成分复杂、毒性高和可生化性差等特点,给处理工艺的安全、稳定运行带来诸多挑战。结合第 1 节中所述案例背景,该系统在实际运行中面临以下安全问题 :1)预处理单元进水水质波动大,pH 值在 3~11 频繁变化,导致调节池内废水的可生化性下降,其 BOD5/COD 值通常低于 0.3,不利于后续生化处理。2)A/O 工艺对进水水质适应性差,水解酸化菌和硝化菌活性不稳定,导致出水 COD 和氨氮浓度超标风险增大,污泥膨胀、发臭现象时有发生。3)系统缺乏有效的过程监控与优化控制手段,难以进行工艺参数实时动态优化,导致药物残留、污泥毒性等因素引起的冲击负荷时有发生,设备和管道腐蚀风险加剧,威胁系统的安全运行。
Part3 基于强化学习的制药废水处理工艺安全优化控制系统设计
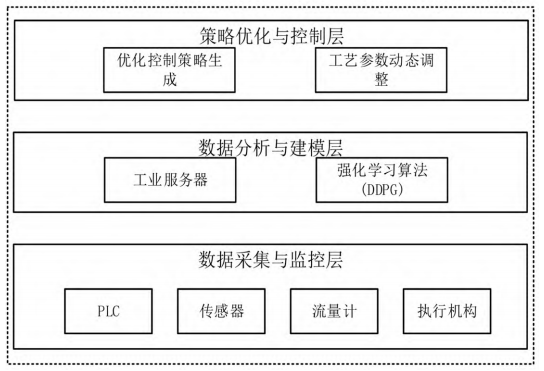
为了解决上述制药废水处理工艺面临的安全问题,本文设计了一套基于强化学习的安全优化控制系统,系统架构如图 1 所示。该系统由数据采集与监控层、数据分析与建模层、策略优化与控制层 3 个部分组成。其中,数据采集与监控层配备了可编程逻辑控制器(Programmable Logic Controller,PLC)、传感器、流量计和阀门定位器等设备,能够实时采集各工艺单元的关键参数,例如进水流量、pH 值、溶解氧(Dissolved Oxygen,DO)、氧化还原电位(Oxidation Reduction Potential,ORP)、混合液悬浮固体浓度(Mixed Liquor Suspended Solids,MLSS)、污泥容积指数(Sludge Volume Index,SVI)等,采样间隔为 5min。数据分析与建模层搭载工业服务器,运行 RL 算法对采集的历史数据进行特征提取与环境建模。策略优化与控制层根据 RL 算法生成的最优控制策略,将优化的控制指令(例如曝气量、回流比和排泥时间等)下发至 PLC,通过变频器、电动阀等执行机构对各工艺参数进行精准控制,并与数据采集层形成闭环,实现全流程动态优化。
图 1 系统架构
系统采用马尔可夫决策过程(Markov Decision Process,MDP)来对制药废水处理系统的环境状态和动作进行建模。
根据第 1 节所述案例背景,选取影响系统安全运行的关键工艺参数作为环境状态变量,包括进水 COD 浓度(s1)、A/O池 pH 值(s2)、DO 浓度(s3)、MLSS 浓度(s4)、SVI(s5)、出水 COD 浓度(s6)等,即环境状态 St 可表示为一个六维矢量,如公式(1)所示。
式中 :t 表示时间步。
系统的控制动作 At 包括调节预处理单元的集水池 pH 值(a1)、A/O 池的溶解氧设定值(a2)、污泥回流比(a3)、剩余污泥排放流量(a4)等,如公式(2)所示。
考虑不同工艺参数的量纲差异较大,需要对状态变量和动作变量进行归一化处理,将其映射到 [0,1] 区间。归一化处理如公式(3)所示。
式中 :x' 为归一化后的值 ;xmin 和 xmax 分别为变量的最小值和最大值。
系统运行过程中获得的即时奖励 rt 可根据出水水质是否达标和设备运行情况来设计 [2]。例如,当出水 COD 和氨氮浓度同时达标时,给予较大的正奖励(例如 rt=1),而当出现设备故障或超标排放等异常情况时,给予较大的负奖励(例如 rt=-1)。
构建合理的环境模型能够为智能代理学习提供必要的先验知识,加快策略迭代收敛速度。在 MDP 框架下,每个时间步内的智能代理根据当前环境状态 St 选择一个动作 At,环境状态随之转移至下一步 St+1,并反馈相应的奖励 rt+1。通过多轮试错与学习,智能代理能够逐步掌握在不同状态下采取最优动作序列的能力,从而实现对制药废水处理全流程的动态优化控制。
训练智能代理是实现工艺参数动态调节的关键环节,其核心作用是采用强化学习算法,使智能代理学会根据环境状态(例如进水 COD 浓度、pH 值等)选择最优控制动作(例如曝气量、回流比),从而降低出水超标风险,减少设备腐蚀,并优化能耗。
本文选用深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法,该算法适合连续动作空间,能够精确应对案例系统中集水池 pH 调节量(a1,6.5~8.5)、A/O 池溶解氧设定值(a2,1.5mg/L~3.5mg/L)和污泥回流比(a3,0.3~0.8)等的连续控制需求。
训练流程如下 :基于第 3.2.1 节构建的马 MDP 环境模型,初始化演员网络(输出动作)和评论家网络(评估动作价值),网络结构采用 3 层全连接神经网络(隐藏层节点数分别为 128 和 64)[3-4]。环境状态 St(包括进水 COD 浓度、A/O 池 pH 值、DO 浓度、MLSS 浓度、SVI 和出水 COD 浓度)经归一化处理后输入,并输出动作 At。为了鼓励探索,在训练初期为动作添加正态分布噪声 N(0,σ),初始 σ=0.15,每1000 轮衰减 10%,最终降至 0.02,以平衡探索与收敛。
奖励函数是训练的核心,会直接影响智能代理的学习方向。为了兼顾出水水质达标与运行成本,奖励函数设计如公式(4)所示。
式中 :I(·)为指示函数(当条件满足时为 1,否则为 0);s6,t 为出水 COD 浓度 ;s2,t 为 A/O 池 pH 值 ;Paeration 为曝气功率,W ;Pmax 为最大功率,Pmax=5000W。
根据案例出水标准(COD 浓度 <400mg/L,氨氮 <35mg/L)优先级设定公式中的权重 0.6、0.4 等。pH 惩罚项能够防止生化菌失活,能耗项能够约束运行成本。例如,如果某时刻s6,t=350mg/L,氨氮 30mg/L,pH=7.0,Paeration=3000W,则有公式(5)。
公式(5)表明系统运行良好。在训练过程中,智能代理与环境交互生成经验数据,存储于经验回放缓冲区(容量 5×105),每批次随机抽取 128 条经验更新网络。将演员网络学习率设为 5×10-5,评论家网络为 5×10-4。为了保证稳定性,目标网络采用软更新,更新系数 τ=0.01。训练的关键注意事项如下 :1)监控奖励均值,如果连续 500 轮波动小于0.03,那么可视为初步收敛。2)检查动作边界,例如如果a3>0.8,那么截断至 0.8,避免泵过载。3)定期检查缓冲区数据分布,防止进水波动(例如 COD 突增至 4000mg/L)导致经验偏倚,必要时清空部分旧数据。训练过程中的关键参数设置及其依据见表 1,可作为实际操作的参考。
在表 1 中,参数设置需要根据案例系统特点(例如进水COD 波动 2500mg/L~4000mg/L)进行优化,保证训练效率与控制精度。训练完成后,智能代理能够根据实时状态输出动态调整工艺参数,为后续控制策略部署提供可靠基础。
表 1 智能代理训练关键参数配置
在基于强化学习的制药废水处理工艺安全优化控制系统中,部署控制策略是将训练好的智能代理应用于实际系统,实现工艺参数实时动态调节的关键步骤。其作用在于采用强化学习(Reinforcement Learning,RL)算法生成的控制策略,并通过闭环控制,保证案例系统在进水水质波动(例如 COD 浓度 2500mg/L~4000mg/L)下维持出水稳定(COD浓度 <400mg/L,氨氮 <35mg/L),并降低设备腐蚀风险。
部署流程如下:将第 3.2.2 节训练好的深度确定性策略梯度(DDPG)演员网络模型嵌入工业服务器,与数据采集与监控层(见第 3.1 节)对接 [5-6],服务器每 5min 接收一次传感器数据(例如进水 COD(s1)、A/O 池 pH(s2)和 DO(s3)),经归一化处理后输入模型,并输出控制动作 At,包括集水池pH 调节量(6.5~8.5)、溶解氧设定值(1.5mg/L~3.5mg/L)、污泥回流比(0.3~0.8)和排泥流量(0m3/h~0.5m3/h)。为了防止动作超限,设置约束条件,如公式(6)所示。
公式(6)能够保证其在物理可行范围内,避免泵过载。例如,如果模型输出 a3,t=0.9,那么调整为 0.8 ;如果输出0.2,那么调整为 0.3。控制动作通过 PLC 下发至执行机构(例如变频器调节曝气泵功率,电动阀控制回流),实现精准调控。
关键注意事项如下 :1)设置动作更新频率为 5min,与传感器采样同步,避免频繁调节导致设备磨损。2)如果检测到异常状态(例如 pH<4 或 >10),那么暂停模型输出,切换至手动模式,以保护生化菌。3)定期校验传感器数据,如果 DO 偏差超 0.5mg/L,那么需要校准设备。
为了验证基于强化学习的制药废水处理工艺安全优化控制系统在实际场景中的应用效果,本文以第 1 节描述的制药企业废水处理系统(处理规模 30m3/d)为试验对象,设计为期 30 天的连续运行试验。试验基于第 3 节构建的 DDPG 强化学习控制系统,设置进水水质变化(COD 浓度 2500mg/L~4000mg/L,氨氮 80mg/L~150mg/L)作为环境变量,系统自动调节的控制参数包括集水池 pH 值(6.5~8.5)、A/O 池溶解氧设定值(1.5mg/L~3.5mg/L)、污泥回流比(0.3~0.8)和剩余污泥排放流量(0m3/h~0.5m3/h)。试验过程中控制温度在(25±2)℃,水力停留时间(HRT)保持一级 A/O 池 18h、二级 A/O 池 14h 不变。试验采用 5min 采样频率记录数据,共收集 8640 个数据点。试验设计了模拟冲击负荷测试(第25 天 COD 浓度突增至 4500mg/L,持续 8h),评估系统应急响应能力。评价指标设置如下 :1)出水水质达标率(目标值 >95%),即 COD 浓度 <400mg/L,并且氨氮 <35mg/L。2)系统能耗(目标值 <1.4kW·h/kg COD)。3)冲击负荷恢复时间(目标值 <5h)。4)工艺参数控制精度(目标值 :DO 控制误差为 ±0.2mg/L,pH 控制误差为 ±0.3)。5)系统安全事件发生率(目标值 <1 次/月),包括污泥膨胀、设备故障等异常情况。数据分析采用描述性统计和时间序列分析方法,以评估系统性能稳定性。
通过 30 天的连续运行试验,获得了基于强化学习的制药废水处理工艺安全优化控制系统的性能数据,见表 2。试验结果显示,该系统在实际应用场景中表现出色,各项指标均达到或超过预设目标值。在出水水质达标率方面,系统达标率为 97.8%,超过了预设目标值(>95%),表明 DDPG算法能够有效处理进水 COD 浓度(2500mg/L~4000mg/L)波动带来的挑战。系统能耗为 1.28kW·h/kg COD,低于目标值 1.4kW·h/kg COD,主要得益于强化学习算法能够根据水质状态实时优化曝气量,避免能源浪费。在冲击负荷测试中,当 COD 浓度突增至 4500mg/L 时,系统仅需 4.2h 就能恢复正常出水水质,优于预设目标(<5h),验证了系统的抗冲击能力。在工艺参数控制精度方面,DO 控制误差(±0.15mg/L)和 pH 控制误差(±0.22)均优于目标值,主要得益于 DDPG 算法的精准控制能力,减少了参数波动对生化系统的不利影响。系统安全事件发生率为 0.7 次/月,低于目标值(<1 次/月),表明系统能够有效预防设备异常和工艺波动,提高运行安全性。试验数据进一步显示,在系统稳定运行阶段,pH 波动幅度降低了 61.4%,溶解氧控制稳定性提高了 60.5%,直接促进了生化菌群活性稳定,是出水水质达标率提高的关键因素。
表 2 试验结果
本文围绕制药废水处理工艺的安全优化,构建了基于强化学习的控制系统,并通过实际案例系统进行了试验验证。结果显示,该方法在多参数动态调节、系统抗冲击能力、能耗降低以及安全事件防控等方面均取得了良好成效。通过采集与建模、策略优化和闭环部署,实现了废水处理全流程智能管控。未来可进一步拓展算法鲁棒性研究,融合更多工艺场景和大规模工业应用,保障智能水处理安全,并提高其自动化水平。
[1] 缪璐,孙晓旭,丁睿 . 混凝—吸附组合工艺处理洗浴废水试验研究 [J]. 江苏水利,2025(4):27-31.
[2] 周言 . 光伏行业高浓度氨氮废水回收处理工艺过程模拟与优化 [J]. 浙江化工,2025,56(3):48-53.
[3] 曹永生 . 环保工程中含难降解有机物的化工废水工艺优化[J]. 石化技术,2025,32(3):439-440,374.
[4] 王好通,张翼然,柴勇利,等 .SBR+ 人工湿地组合工艺处理畜禽养殖废水 [J]. 水利科技与经济,2025,31(3):1-6.
[5] 刘韵,张慧敏,裘湛,等 . 污水处理系统中微生物群落结构及其对环境因子响应研究进展 [J]. 净水技术,2025,44(3):19-26.
[6] 陈韦帆,周丽玲,陈家斌,等 . 化学沉淀法处理含铊钢铁废水研究及应用进展 [J]. 净水技术,2025,44(3):35-43,85.






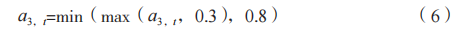




















评论
加载更多