
水溶性和渗透性差被认为是限制口服药物生物利用度的主要原因。事实上,这些都是理论框架的整体考虑因素,如Lipinski的“5规则”,生物药剂学分类系统(Biopharmaceutical Classification System,BCS)和扩展的可开发性分类系统(Developability Classification System,DCS),它们提供了区分有前景的口服药物的方法。据报道,随着时间的推移,越来越多的小分子候选药物表现出可能阻碍口服吸收的特性。事实上,自“5规则”首次提出以来的20年里,经FDA批准的新化学分子实体(new chemical entities,NCE)的分子量和计算出的水-正辛醇油水分配系数(clogP)都有所增加,也就是说现在NCE的水溶性越来越差,脂溶性越来越高。总体来说,不那么传统的类药分子的成功临床获批,强调了药物配方的关键作用。
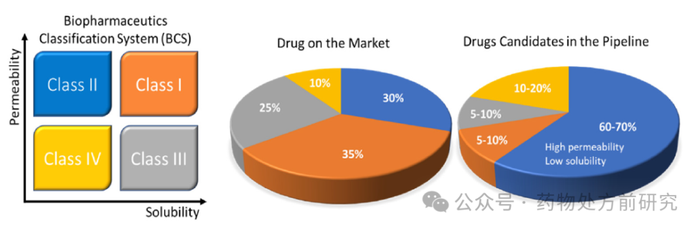
先进的以脂质为基础的配方策略能够增强水溶性差和/或肠通透性低的药物(即BCS II和IV类药物)的口服吸收。其中一个例子是自乳化药物递送系统SEDDS,它是油、表面活性剂和/或助溶剂的组合,在胃肠道的水环境中自发乳化。SEDDS制剂提高口服生物利用度的能力可归因于多种机制,特别是通过提高亲脂性药物的表观溶解度,以及减少代谢或外排。因此,一些临床获批的药物依赖于SEDDS配方的递送,包括环孢素a(例如,Sandimmune,Neoral),替那韦(例如,Aptivus)和非诺贝特(例如Lipofen)等。

尽管SEDDS在理论上相对简单,但设计这种处方的路径仍然不是简单的。传统的SEDDS开发方法是一个依靠反复试错来筛选、优化和评估配方的经验过程。最相关的问题之一在于选择合适的脂质辅料及其混合物。通常,首先需要定量测定药物在辅料中的溶解度,然后通过目测评估,根据其乳化特性筛选脂质辅料的混合物。考虑到SEDDS可能的辅料范围(即油、表面活性剂、助溶剂,所有这些辅料在亲水性/亲脂性、纯度等方面可能有所不同),通常根据公认的安全(generally recognized as safe,GRAS)状态来缩小辅料选择范围。脂质制剂分类系统(Lipid-based Formulation Classification System,LFCS)是促进脂质制剂开发过程的既定工具。LFCS根据其成分定义了四类口服脂质制剂,其本质范围从纯油混合物到纯表面活性剂和助溶剂的组合。SEDDS即为LFCS Type II和Type III的处方,也是目前研究较多的脂质制剂。
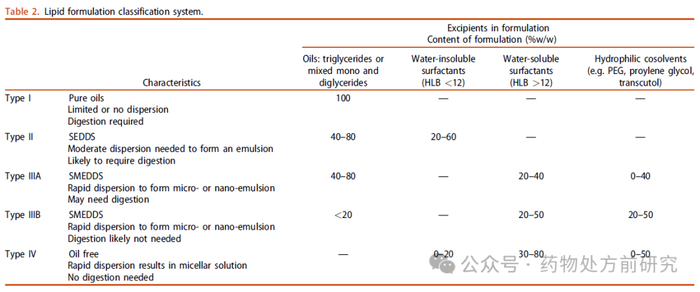
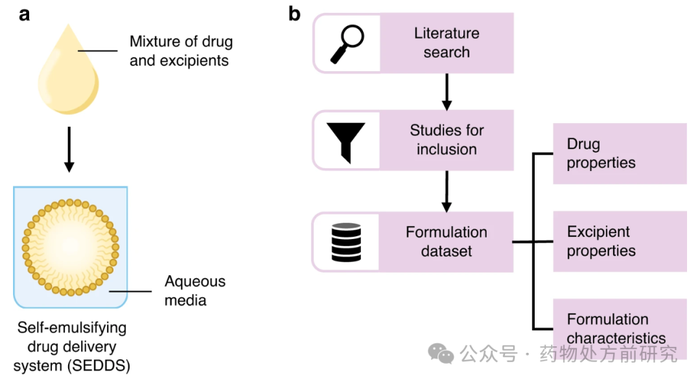
虽然LFCS将这些成分范围与典型性质联系起来,但它并没有通过探索各种辅料组合来消除开发定制配方的需要。尽管如此,从传统的SEDDS开发转变的方法已经出现,主要采用数据驱动的工具。近年来,人们对人工智能(artificial intelligence,AI)和机器学习(machine learning,ML)在制药科学(包括药物配方)中的整合产生了浓厚的兴趣。这些工具已被用于各种先进的应用,从快速设计聚合物长效注射剂到工程肽的持续递送到眼睛,以及用于脂质纳米颗粒递送mRNA的可电离脂质的开发。
在口服脂质制剂的背景下,ML和计算技术在早期开发中发挥了作用,特别是基于小分子药物溶解度的筛选。初步ML模型已用于预测脂质制剂中的药物过饱和以及SEDDS分散后药物表观溶解度的增加。在这些情况下,研发人员只研究了有限数量的配方组合物,很少有对SEDDS成分进行广泛调查。一个例子包括整合ML和分子动力学来预测SEDDS配方的自乳化区域的方法,该方法还报告了数据集中辅料的分布。然而,这项研究没有确定数据集中配方中的药物。因此,尽管SEDDS是一种完善的配方策略,但目前还没有针对配方组成的开放获取的SEDDS数据集。Jonathan Zaslavsky & Christine Allen的工作提供了一个包含668个独特配方的SEDDS数据集,其中包含药物、辅料和配方特征,可用于更好地理解组成模式或关系,并预测配方性质,如下图所示。Jonathan Zaslavsky & Christine Allen的数据集为SEDDS配方的开发做出了贡献,提供了一个有文件记录的配方和相关信息资源,可以作为辅料选择和筛选的起点。
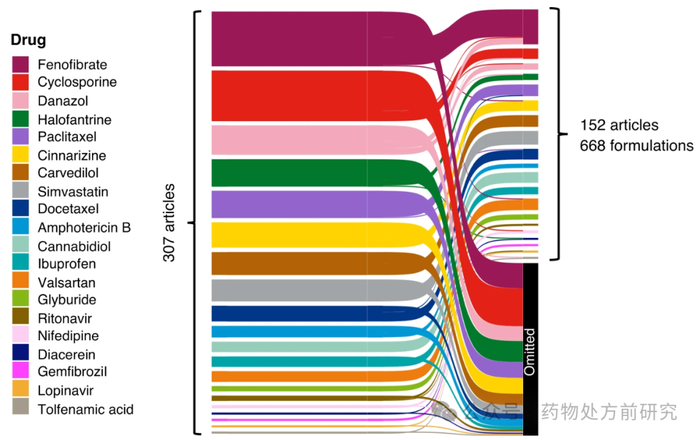
Jonathan Zaslavsky & Christine Allen的数据集中所有SEDDS配方均来自已发表的文献。该数据集是基于对Web of Science数据库的搜索而构建的,该数据库覆盖了Web of Science数据库建立至2023年3月,使用关键词“self-emulsifying drug delivery systems”或“SEDDS”或“SNEDDS”或“SMEDDS”和“drug”,从20种低水溶性药物(即active pharmaceutical ingredients(API))列表中选择“drug”。搜索结果仅限于文章,并通过出版商(即Elsevier, Springer Nature, Taylor & Francis, Wiley, MDPI)进行过滤。作者人工筛选了307篇文章的初始库,产生了152篇文章,其中包含668种独特的配方,用于纳入数据集,如下图所示。没有提供相关信息的文章被省略,例如配方成分细节不足,配方描述与所讨论的药物不对应,或非唯一配方。完整的源研究列表在sedds_dataset_full.csv文件的源和DOI列中提供。
数据集中获得的单个样本信息包括药物的特性和相对比例,以及每种辅料(即油、表面活性剂、助溶剂和其他成分)。其他添加剂或成分按功能分组(例如,吸收增强剂,沉淀抑制剂等),而不是单独的身份,以方便下游分析。给定配方中每种成分的比例被标准化为成分数据,这样它们的重量单位总计为100%。其他描述符包括平均粒径(即分散时SEDDS的液滴直径)和平均液滴多分散性指数PDI。还包括一个手动定义的描述符,表示给定的配方是否在其源文章的上下文中被发现是有希望的。如果一种配方被选中进行进一步开发和/或从一组筛选的配方中显示出最有利的特性(即取决于原始研究),则该配方被认为是有前途的。
通过附加与每个公式的每个组成部分相关的附加特征,进一步扩展了文献挖掘的数据集。药物的理化性质来源于DrugBank,而辅料的性质根据文献和供应商或制造商信息报告。为了获得一个易于处理的数据集,以适应下游分析和建模,进行了数据清理和预处理。首先,辅料的商品名称全部转换为化学名称,以消除冗余。对于每种配方,计算油、表面活性剂、助溶剂或其他成分的数量,并将其转换为单个所谓的SEDDS复杂性特征。该特征是对每种配方(x)中的成分总数进行最小-最大归一化,根据下面的公式计算:
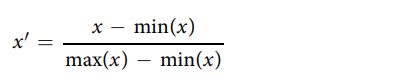
此外,描述该配方的油、表面活性剂和助溶剂性质的特征是从各个组分的性质推导出来的。例如,使用某种油(或油的混合物)中的优势脂肪酸,二元特征是否存在长脂肪链和/或饱和链来描述配方的油特性。对于表面活性剂和助溶剂的特征,根据配方中每种辅料的比例计算重量平均性质。
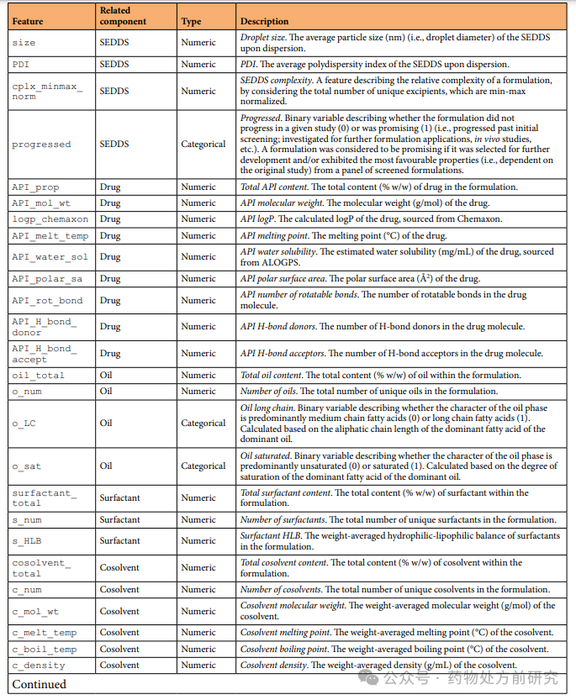
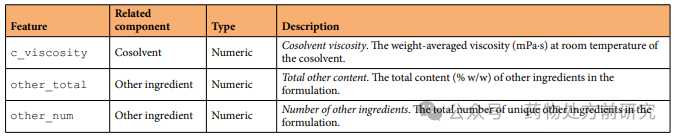
SEDDS数据集及相关数据以CSV格式在Open Science Framework(OSF)上提供,下表提供了可用文件的摘要。Components文件夹中包含的数据文件报告了所有单个药物和辅料及其相关属性,并在最终数据集中进行了整理,sedds .csv。该数据包含20种药物,44种独特的油,31种独特的表面活性剂和17种独特的助溶剂。总的来说,最终整理的数据集包含668个SEDDS公式的29个特征,如下表所示。

鉴于数据集来源于文献,所以有效性与源研究的质量直接相关。因此,报告数据的稀疏性和准确性以及出版偏倚的影响等方面的限制是可以预料的。通过纳入一系列药物及其所有可用的SEDDS配方,作者努力赋予数据集更具代表性的样本广度(即,BCS II和IV类药物的组合;一些药物比其他药物更不适合SEDDS配方)。此外,研究评估了信息的完整性和报告配方的独特性。这确保了每个样品的所有成分细节都可用。来自源研究的所有可能的特征都包含在数据集中,但是有可能用额外的描述符扩展它,例如结构化表示(例如,用于药物或辅料),以便研究人员在ML应用中使用数据集。值得注意的是,并非所有案例都报告了SEDDS的液滴大小和分散后的PDI,只有506个(75.7%)制剂报告了前者,289个(43.3%)制剂报告了后者。虽然这与数据的性质有关,但缺失的数据可以通过代入、应用合成数据生成技术或通过遗漏来解决。













评论
加载更多